Installation d’un cluster
L’installation sur le premier noeud/control se fait via le script fourni par K3S (après vérification).
Pour installer des noeuds supplémentaires, il faut passer en argument K3S_URL et K3S_TOKEN.
Pour K3S_URL, c’est https://<mon premier noeud>:6443 (vérifier que c’est joignable avant !)
Pour K3S_TOKEN, on le trouve sous /var/lib/rancher/k3s/server/node-token sur le premier noeud.
Par la suite, le premier noeud devient serveur tandis que les autres deviennent des agents.
Il sera intéressant de remonter ces informations par une installation par ansible par exemple, car il faudra les fournir à chaque installation.
Interaction avec le cluster
Il faut récupérer le fichier de configuration du premier noeud et le mettre dans la machine de management.
Source = /etc/rancher/k3s/k3s.yaml
Target = ~/.kube/config
Il faut installer kubectl sur la machine de management.
Attention à ne pas confondre kubectl et kubeadm.
Ce dernier sert à initialiser et configurer le cluster K8S, ce n’est pas ce qu’on recherche pour l’instant.
kubectl quand à lui sert à contrôler ce qui tourne sur le cluster.
ssh myadmin@node-00.watylocal "sudo cat /etc/rancher/k3s/k3s.yaml" \
| sed "s|127.0.0.1|node-00.watylocal|g" > ~/.kube/config
Lors des appels kubectl tests, j’ai une erreur sur le certificat. Celui-ci n’est pas valide pour node-00.watylocal, seul node-00. Le problème vient du fait que lors de l’installation de k3s et de la création de son certificat, le node 0 n’avait pas comme fqdn .watylocal. Donc le certificat s’est mal généré.
Pour réparer:
- changer resolved conf pour inclure ‘search watylocal’
- ajouter le SAN (Subject Alternative Name) dans la config kubernetes:
sudo tee /etc/rancher/k3s/config.yaml <<EOF
tls-san:
- node-00.watylocal
EOF
sudo systemctl restart k3s
Après ça, il faut récupérer à nouveau la config yaml.
kubectl version marche depuis la machine de management.
L’utilisation de kubectl directement devient vite limité.
En effet, pour déployer son application ou son site web, quelques fichiers déclaratifs suffiront.
Par contre, dès que les applications deviennent grosses et complexes,
il faut passer par une solution pré-packagée.
Gestionnaire d’applications Helm
La théorie
On peut voir Helm comme le gestionnaire d’applications pour Kubernetes.
L’éditeur d’une solution ou la communauté prépare un ensemble de fichiers afin de définir l’installation de l’application. Ainsi, les différents objets Kubernetes (Pods, Deployments, etc) sont préparés via des templates et des valeurs par défaut afin d’avoir une installation simplifiée de l’application sur un cluster.
L’ensemble des fichiers templates, valeurs (values) ainsi que d’autres sont regroupés dans un (une?) Chart.
Via Helm et depuis un dépôt de code (repo), on installe une Chart sur un cluster sous forme de Release (on peut modifier les valeurs par défaut).
Pour les principales commandes,
helm list et helm get interagissent avec les releases.
helm repo list, helm search repo et helm show interagissent avec les charts.
La pratique
J’installe Helm depuis la page de releases (https://github.com/helm/helm/releases). J’unpack puis move dans /usr/local/bin/.
On ajoute les repos puis on installe les applications Prometheus et Grafana:
helm repo add grafana https://grafana.github.io/helm-charts
helm repo add prometheus https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus/prometheus
helm install grafana/grafana
Test de connection :
sur la machine de management:
kubectl port-forward svc/prom-release-prometheus-server 9090:80En fait cette commande ouvre le port 9090 du localhost (donc de la machine de management) vers le port 80 du service.depuis le laptop:
ssh -L 9090:localhost:9090 admin@mngmt -NIci on fait du port forward de localhost:9090 vers le port 9090 de la machine de management.se connecter sur navigateur de laptop, http://localhost:9090 => ça marche !
Ce petit test permet de vérifier que l’application tourne effectivement sur le cluster et qu’avec le bon accès on peut s’y connecter. C’est donc bien fonctionnel mais non-robuste.
Accès aux applications
Maintenant que les applications Prometheus et Grafana sont installés, nous allons y accéder.
Le cahier des charges des accès est simple:
- Depuis Internet pas d’accès.
- Depuis mon réseau maison, accès aux services exposés (sites web/gui, dashboards etc).
- Depuis mon réseau homelab, accès complet.
Je veux également y accéder via un nom et pas une adresse IP.
Réseau
Pour la partie réseau, gérer les accès Internet et homelab est simple. La partie plus compliqué est pour le réseau maison.
En gros le schéma c’est :
ordi portable –> OPNSense –> noeud cluster (?) –> service/pod/autre
Pour atteindre l’intérieur du réseau homelab, il y a quelques difficultés. Je suis derrière une box internet donc les capacités d’interactions sont soit faible soit manuelles. Je pourrais installer un pi-hole mais je devrais changer le DNS cible sur toutes les machines présentes et futures (téléphones compris).
Dans la box j’ai une option “DNS” qui me permet d’associer une IP avec un nom. Je ne veux pas faire ça pour tous mes services. Avec un système automatique (nouveau service online -> publication du service dans un DNS) pourquoi pas mais là, non.
Mes accès aux services se feront donc avec un sous-chemin (subpath). Ainsi mon accès Prometheus sera https://services.watylocal/prometheus et mon accès Grafana https://services.watylocal/grafana.
Dans l’onglet DNS de ma box j’ajoute l’association “services.watylocal” avec l’IP OPNsense “WAN”.
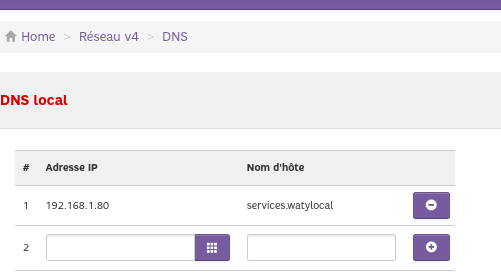 Ainsi les appels depuis le réseau maison partiront vers OPNsense directement,
la porte d’entrée la plus sécurisée pour des flux entrants.
Ainsi les appels depuis le réseau maison partiront vers OPNsense directement,
la porte d’entrée la plus sécurisée pour des flux entrants.
Dans OPNsense, je vais configurer un Network Address Translation (NAT) afin
de faire correspondre un appel sur l’IP OPNsense depuis l’extérieur vers une adresse dans le sous-réseau.
Pour cela, il faut aller dans Firewall > NAT > Port Mapping.
L’inconvénient pour l’instant c’est que l’IP cible est celle d’un noeud,
donc sujette à sauter éventuellement.
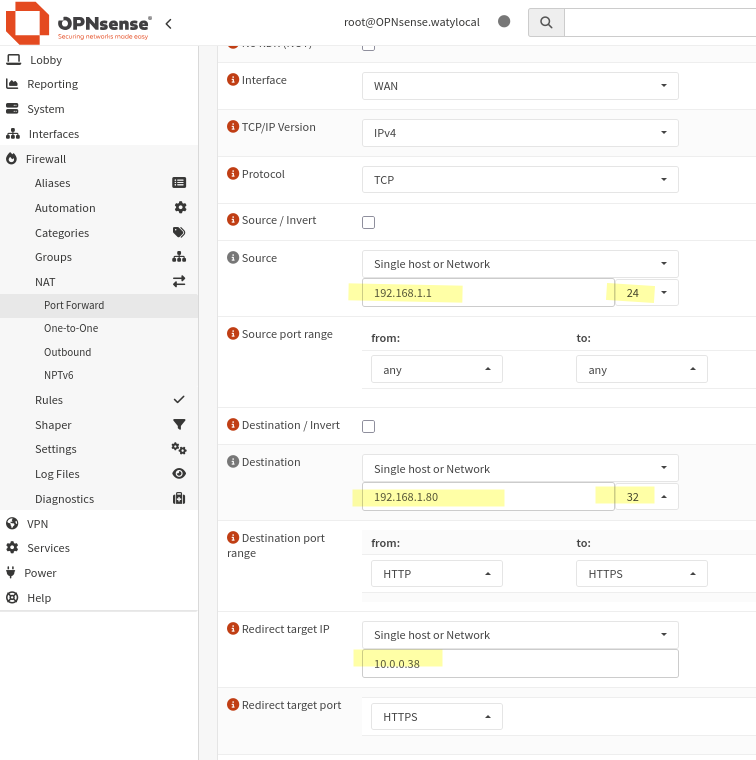
En testant le port forwarding kubernetes sur ce noeud, on accède bien à l’application ! La partie réseau est donc OK.
Kubernetes
Ma première installation de Prometheus et Grafana s’est faite avec les valeurs par défaut, aucun Ingress n’était paramétré. En conséquence, il était impossible d’accéder aux applications depuis l’extérieur du cluster sans port-forwarding. Le service “prometheus-server” est défini sur un cluster_ip.
En recherchant les différents moyen d’exposer Prometheus (NodePort, LoadBalancer, Ingress, etc), l’utilisation de l’Ingress m’a semblé la plus appropriée. Passer par un NodePort expose trop le cluster et serait problématique en cas de perte de noeud. Pour LoadBalancer, je ne suis pas dans le cloud où les loadbalancers partenaires sont paramétrables depuis Kubernetes. Je ne veux pas non plus installer MetalLB pour l’instant.
De plus, dans la documentation Kubernetes j’ai trouvé exactement l’architecture
que je recherche dans mon installation, le “fanout” : https://kubernetes.io/docs/concepts/services-networking/ingress/#simple-fanout.

Dans notre déclaration d’Ingress, on fait correspondre chaque sous-chemin (subpath ou prefix) avec un service existant.
IMPORTANT
L’objet Ingress doit être dans le même namespace que le service cible, quand bien même l’Ingress Controller est dans un autre namespace.
Dit comme ça, ça paraît simple, mais en fait dès qu’un seul paramètre est faux l’application ne fonctionne pas ou est inaccessible. Un exemple d’une partie des problèmes se trouve à https://stackoverflow.com/questions/61121046/ingress-routing-rules-to-access-prometheus-server.
Pour résumer, une installation “par défaut” de prometheus ou grafana “s’attend” à se trouver, quelque soit l’adresse IP ou le nom d’accès, derrière la racine (le dernier “/” après l’adresse). Cependant, dans le cas d’un fanout, le service se trouvera derrière “/<nom du service>”.
Sans paramétrage préalable et même si l’accès initial fonctionne, le serveur ne pourra pas résoudre ses liens internes car sa façon de produire ses liens ne correspond pas à la réalité. Il faut donc customiser chaque release Helm afin que chaque serveur puisse résoudre ses différents liens internes.
Pour cela, il faut changer certaines “values” existantes et les surcharger avec notre contexte. Les variables sont différentes selon les services mais le principe est le même. Le paramétrage doit inclure le domaine “de base” (ici services.watylocal) et doit inclure le préfixe ("/prometheus" et “/grafana” dans les exemples).
Ensuite, côté Ingress, il faut faire matcher le domaine + le prefix avec le service visé. Avec Traefix (shippé par défaut avec K3S), on réalise un IngressRoute. Le match se fait ainsi :
match: Host(`services.watylocal`) && PathPrefix(`/prometheus`)
Les fichiers values et ingress sont visible dans le boilerplate kubernetes.
Bilan
L’installation des applications Prometheus et Grafana, deux standards du monitoring dans l’IT est riche d’enseignement.
Explorer les concepts et décortiquer les différents objets Kubernetes est très formateur.
La difficulté imposée par l’architecture (nodes dans un sous-réseau plutôt que des containers sur machine) devient finalement un atout pour approcher son travail de conditions réelles.